本文介绍如何使用TensorFlow实现transE。为了突出重点,先介绍如何用TensorFlow实习transE的主要代码,后介绍如何准备所需的数据。
2016-09-06更新:入门TensorFlow的好资源
几个需要设置的常量
- embedding_size: embedding的纬度,指每一个embedding有多少维;
- vocabulary_size: embedding的个数,也就是一共有多少个embedding,它其实是实体的个数和关系的个数之和;
- batch_size: batch的大小,指每一个batch中包含了多少个三元组;
- margin: 指正例和负例之间的间距,在知识表示-TransE这篇文章中,就是公式中的\(\gamma\);
- learning_rate: 学习率,是指梯度下降时设置的学习率;
- epochs_num: 训练轮数,就是指训练多少轮然后停止训练。
构建transE的框架
首先要明确,我们的目的是得到所有实体和关系的embedding;我们的输入是正例和负例(的batch)。
如何传入数据
首先简单介绍一下TensorFlow的基本工作方式。使用TensorFlow时需要我们先构建好整个网络的框架,然后通过特定的方式将真实数据传入到框架中进行计算并返回得到的结果。之所以要这么做,是为了方便TensorFlow对整个网络进行求导等操作。这跟python中直接操作数据进行计算是有所不同的。
那么问题来了,在构建网络的时候,用什么来表示之后要传入的真实数据呢?在TensorFlow中,有一个专门的函数来实现这个功能:
tf.placeholder()
从名字也可以看出,就是占位符的意思。我们需要输入正例和负例的batch,因此我们需要两个placeholder:
pos_triples_batch = tf.placeholder(tf.int32, shape=[batch_size, 3])
neg_triples_batch = tf.placeholder(tf.int32, shape=[batch_size, 3])
其中的tf.int32指的是输入的数据的类型,shape是指输入数据的shape。
构建embedding_table
所谓embedding_table可以想象成一个列表,它其中的每一个元素就是一个实体或者关系的embedding。这样我们就可以根据实体(或者关系)的ID来找到它对应的embedding。
如何构建它呢?很简单,使用TensorFlow的Variable函数即可:
embedding_table = tf.Variable(init_embedding_table_value)
这个init_embedding_table_value是什么呢?其实就是一个python中的列表,它包含了vocabulary_size个值,每个值是一个embedding_size纬度的列表。我们可以用如下的语句来得到它的值:
init_embedding_table_value = tf.truncated_normal([vocabulary_size, embedding_size], stddev=1.0 / math.sqrt(embedding_size))
这样我们就构建并初始化好了embedding_table。
TensorFlow中提供了一个贴心的函数,能够让我们非常方便的从embedding_table中取得我们需要的embedding。这个函数就是
tf.nn.embedding_lookup(embedding_table, triples_batch)
下图展示了如何通过embedding_lookup函数将triples_batch转化为triples_embedding_batch
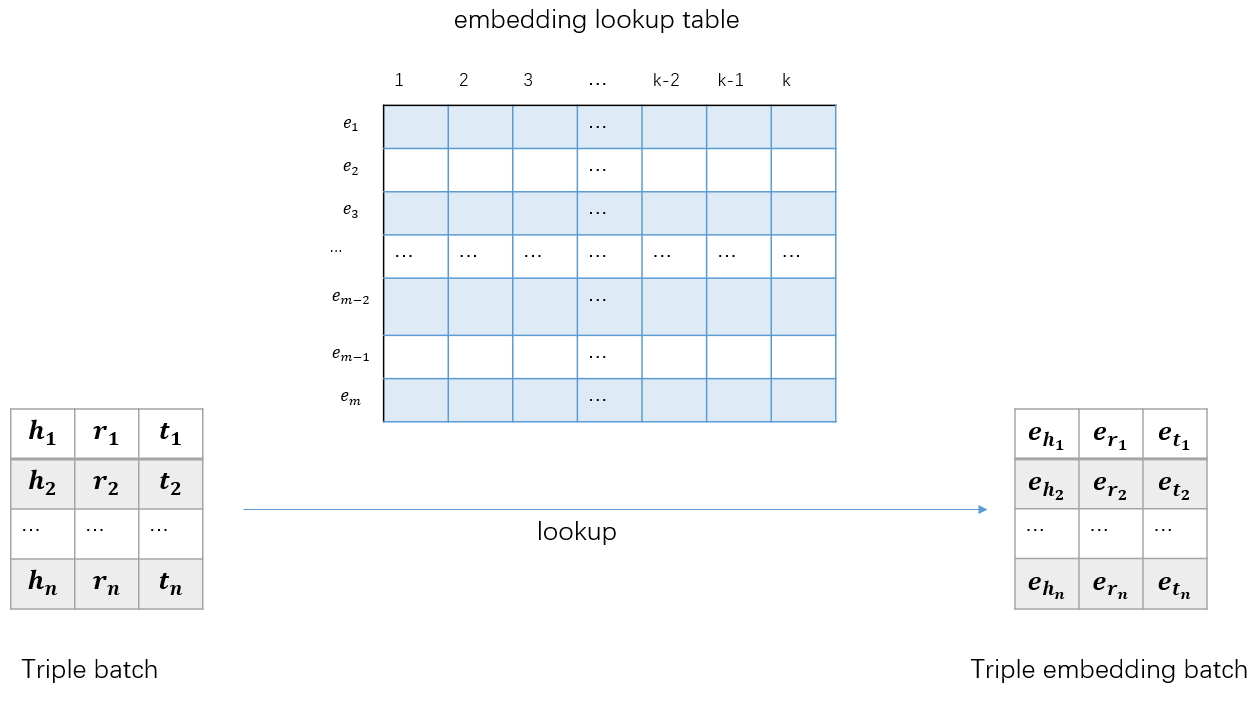
至此,我们已经构建好了能够将输入的三元组batch转为对应的embedding batch的功能。接下来就是构建损失函数了。
损失函数
首先是计算正(负)例batch的能量:
def l1_energy(batch):
return tf.reduce_sum(tf.abs(batch[:, 0, :] + batch[:, 1, :] - batch[:, 2, :]), 1)
p_loss = l1_energy(pos_embed_batch)
n_loss = l1_energy(neg_embed_batch)
这里计算的是batch的\(l_1\)能量,也就是头实体的embedding加上关系的embedding减去尾实体的embedding,然后将每一维(总共有embedding_size维)的值相加得到这个三元组的\(l_1\)能量。上式计算得到的是\(l_1\)能量batch。
然后我们要计算正例三元组的\(l_1\)能量和与之对应的负例三元组的\(l_1\)能量之差,然后加上margin。
margin + p_loss - n_loss
如果上式结果小于0,我们就取0,如果大于0,就取结果本身。这可以通过下面这个函数来实现:
tf.nn.relu()
最后将batch中的每个值求和,得到整个batch的能量,也就是损失。
loss = tf.reduce_sum(tf.nn.relu(margin + p_loss - n_loss)
如此,我们得到了这组batch的损失。
梯度下降法优化embedding值
我们已经得到了loss,在TensorFlow中可以直接调用优化函数来优化所涉及到的embedding值。
optimizer = tf.train.AdagradOptimizer(learning_rate).minimize(loss)
如此我们已经完成了整个网络的构建,接下来就是如何传入真实数据并计算了。
运行
TensorFlow要求开启一个session,然后通过session来运行网络,所以我们首先要构建一个session。这也很简单:
sess = tf.Session()
然后我们需要初始化之前网络中设置的变量(如embedding_table的初始值),我们可以方便的用下面的语句完成:
sess.run(tf.initialize_all_variables())
接下来就可以正式把真实数据传入到网络中去了。如何传入呢?还是要用到sess.run()这个函数。先看代码:
loss_val, opt = sess.run([loss, optimizer], feed_dict={pos_triples_batch: p_triple, neg_triples_batch: n_triple})
第1个参数是一个列表[loss, optimizer],表示我们需要计算网络中这两个变量的值,它们的返回值就赋给等号左边的变量loss_val, opt。真实数据通过第2个参数传入,它是一个字典类型的变量,key是需要placeholder的变量名,value是真实的数据。
这样就完成了一次数据的计算。但是通常我们需要训练很多轮,因此我们可以用循环把上述代码包进去,依次将各个batch传入网络进行计算。
代码
下面是主要部分的代码:
def l1_energy(batch):
return tf.reduce_sum(tf.abs(batch[:, 0, :] + batch[:, 1, :] - batch[:, 2, :]), 1)
embedding_table = tf.Variable(tf.truncated_normal([vocabulary_size, embedding_size], stddev=1.0 / math.sqrt(embedding_size)))
pos_triples_batch = tf.placeholder(tf.int32, shape=[batch_size, 3])
neg_triples_batch = tf.placeholder(tf.int32, shape=[batch_size, 3])
pos_embed_batch = tf.nn.embedding_lookup(embedding_table, pos_triples_batch)
neg_embed_batch = tf.nn.embedding_lookup(embedding_table, neg_triples_batch)
p_loss = l1_energy(pos_embed_batch)
n_loss = l1_energy(neg_embed_batch)
loss = tf.reduce_sum(
tf.nn.relu(
margin + p_loss - n_loss))
optimizer = tf.train.AdagradOptimizer(learning_rate).minimize(loss)
with tf.Session() as sess:
sess.run(tf.initialize_all_variables())
for step in range(epochs_num):
p_triple, n_triple = next_train_batch(batch_size)
feed_dict = {pos_triples_batch: p_triple, neg_triples_batch: n_triple}
loss_val, _ = sess.run([loss, optimizer], feed_dict=feed_dict)
print("step %d, loss_val %f" % (step, loss_val))
需要指出的是,这里没有介绍next_train_batch(batch_size)这个函数,这个函数需要我们自己实现,作用是每次调用时返回下一组batch。另外,为了突出主要的结构,代码中省略了许多约束,这些约束会使得训练出来的结果更好。最后,如果想了解更多TensorFlow自带的函数的用法,可以参照其官网的API
数据的准备
后面在填坑吧~

This work is licensed under a CC A-S 4.0 International License.