本文简要介绍强化学习的基本内容(图写的比较详细,后面可能会再补充一些文字)
Q-learning
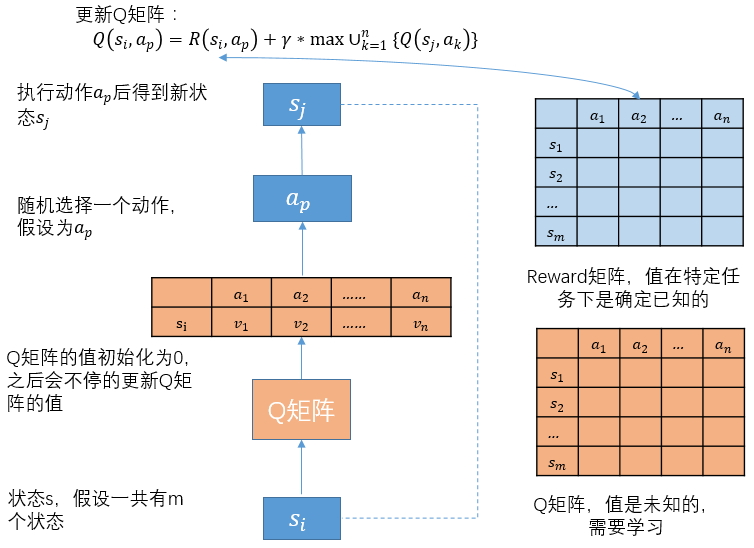
学习过程
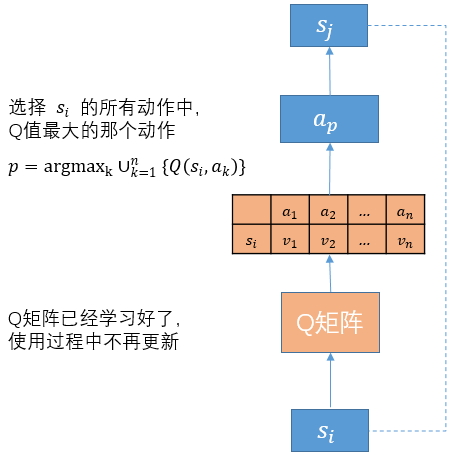
使用过程
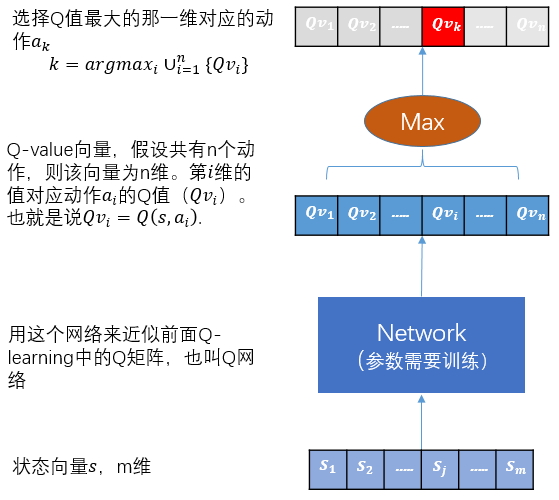
DQN
Overview
从状态s选择动作\(a_k\),再获得奖励\(r_{s,a_k}\)和下一个状态\(s'\),整个过程可以用元组\((s,a_k,r_{s,a_k},s')\)来记录。
输入状态s,输出每个动作的Q值,执行Q值最大的那个动作,这里是\(a_k\)。
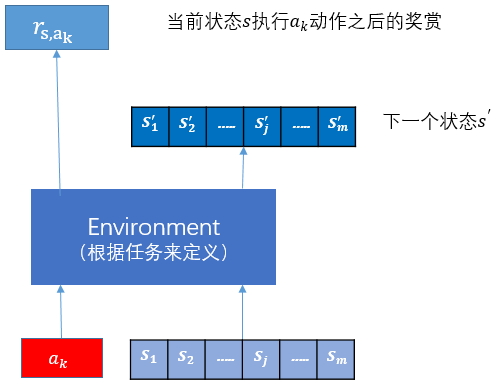
状态s下,执行动作\(a_k\)(它的Q值最大)后,得到奖赏值\(𝑟_{𝑠,𝑎_𝑘}\)和下一状态\(s'\)。
如何训练Q网络
思路
Q网络的输出是每个动作的Q值。而我们希望\(𝑄(𝑠,𝑎_𝑘)=𝑟_{𝑠,𝑎_𝑘}+𝛾*maxU^n_{𝑘=1}\{𝑄(𝑠^′,𝑎_𝑘 )\}\)。(注意只有在网络已经训练好了之后等式才会成立,我们训练的目标就是让这个等式成立。)
做法
- \[x=𝑠\]
-
\(y=𝑟_{𝑠,𝑎_𝑘}+𝛾*maxU^n_{𝑘=1}\{𝑄(𝑠^′,𝑎_𝑘 )\}\)。如果𝑠′是终止状态,那\(𝑦=𝑟_{𝑠,𝑎_𝑘}\)
- \[Loss=(y−𝑄(𝑠,𝑎_𝑘 ))^2\]
技巧
- 每对一个状态生成元组\((s,a_k,𝑟_{𝑠,𝑎_𝑘},s')\)后,将其保存到memory中
- 然后从memory随机抽取batch大小个元组作为训练样本
- 训练网络

This work is licensed under a CC A-S 4.0 International License.