以BERT为代表的预训练语言模型比“传统”的深度学习模型效果有明显的提升,并且BERT模型可以很容易的支持诸如分类、序列标注等常用NLP任务。
但是预训练语言模型通常包含了数量巨大的参数,使得模型在实际生产环境中难以满足实时率的要求。 我们在实践中采用模型蒸馏的方式来克服模型参数过大导致的问题。
模型蒸馏时,student模型的性能通常会比teacher模型的性能有所下降。我们在实践中发现,蒸馏过程中引入大量无标签数据可以让student模型的性能尽可能接近(甚至超过)teacher模型的性能,从而实现“鱼与熊掌兼得”。
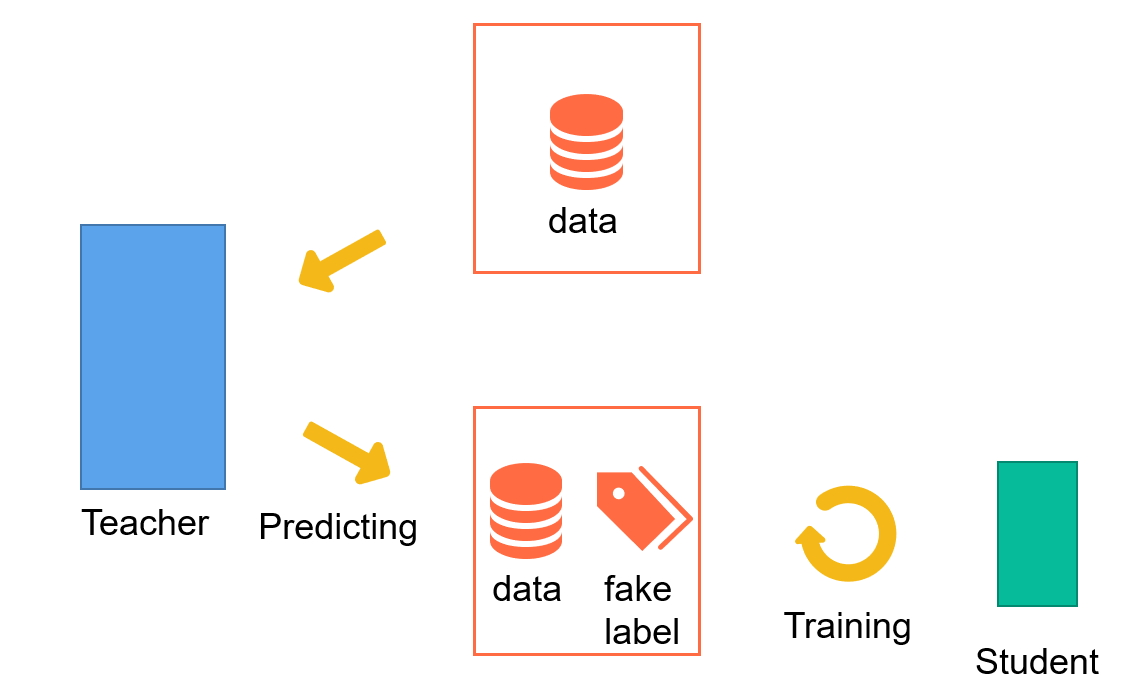
具体来说,我们让teacher对每条数据进行预测,并保存teacher最后分类层给出的logits。对于student,给定一条数据,它的目标便是拟合teacher的预测结果。 teacher的预测结果是指logits经过softmax之后得到的概率分布。 那为什么不直接保存teacher的概率分布而是保存logits呢?理由是保存logits更加灵活。 蒸馏过程中通过teacher的logits计算概率分布时,通常还会考虑一个参数:蒸馏温度。如果一开始保存的就是teacher的概率分布,就无法再使用蒸馏温度进行调整了。

This work is licensed under a CC A-S 4.0 International License.